为什么 Cubox 要将不同的网页文章,解析为 Cubox 自己的文章视图?理由有很多:沉浸无干扰的阅读体验,数据的长期保存,随时标注记录灵感和想法,全文搜索,离线访问能力...
但我们的核心出发点只有一个:当散落在万维网的信息,经过统一格式化处理,真正成为自己的「个人数据」之后,个人的信息管理、知识管理才有无限可能。这和我们一直提倡的「去碎片化」息息相关。
如何准确地将网页解析为文章,是碎片化加剧的环境下,越来越有挑战的事情,也是我们一直努力探索的重点。
在之前的版本中,Cubox 对收藏内容的解析处理主要分为两类:
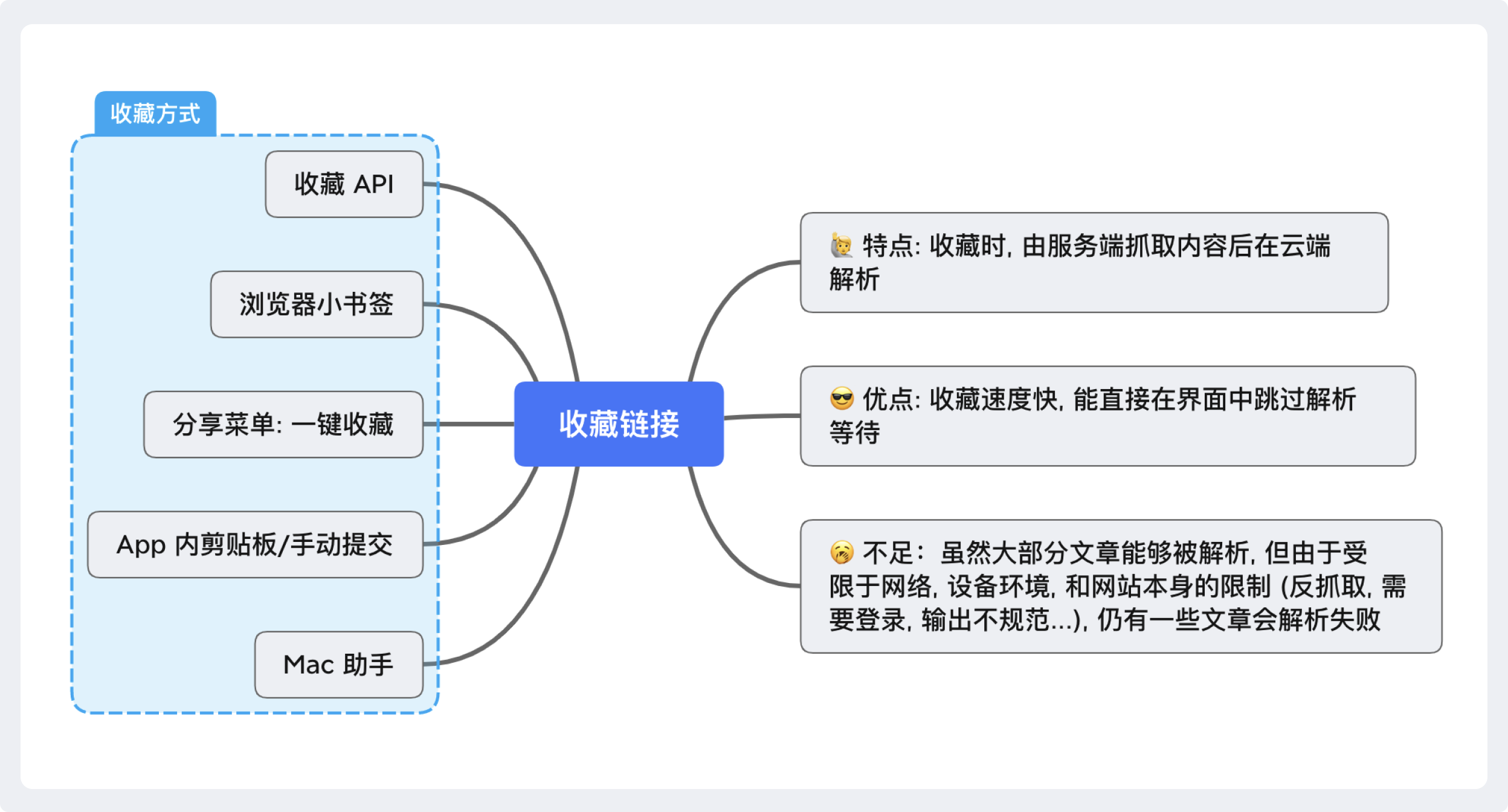
第一类:直接收藏链接
第二类:收藏页面内容
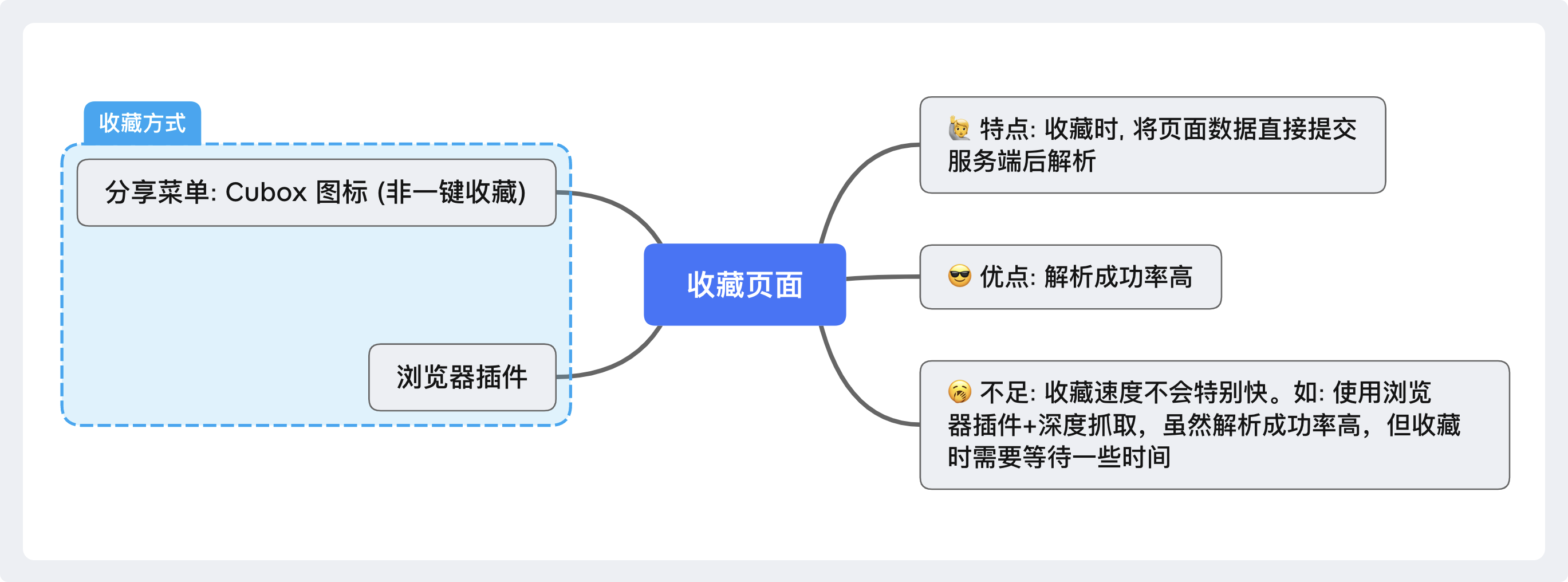
两种处理方式简单总结:
- 云端抓取解析,收藏速度快但解析准确率低;
- 前端提交页面解析,成功率高但收藏速度慢影响体验。
作为一个以收藏内容为核心的工具,我们该如何权衡抓取速度和解析成功率,以提供优秀可靠的方案?
Cubox 移动端 6.1 版本是我们给出的阶段性成果:云端中心化 + 分布式设备 = 融合解析。
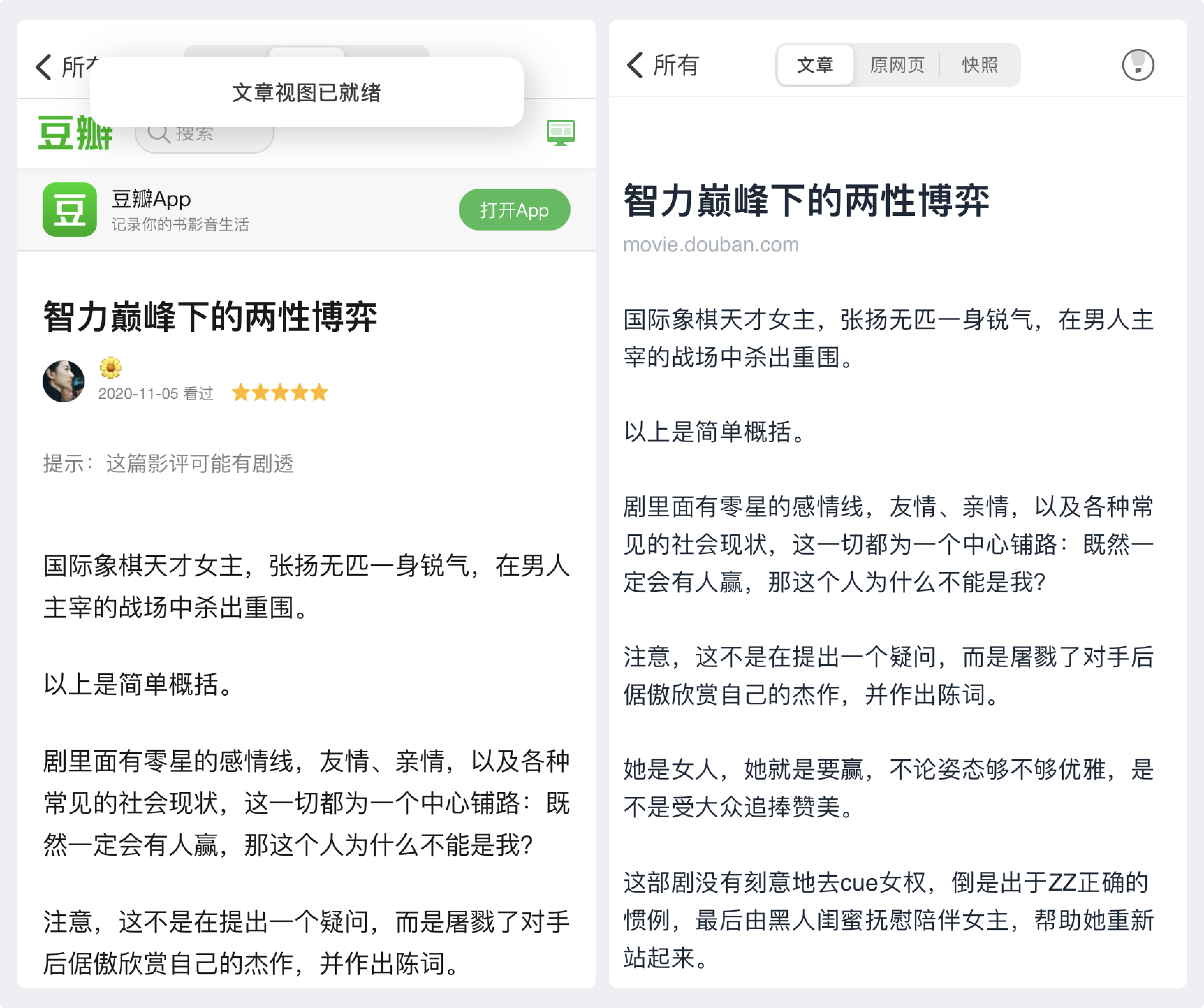
访问网页时,自动重试解析
如果收藏的文章没能被解析,当在客户端打开「原网页」视图时,将自动在本地尝试解析,解析完成后将显示「文章已就绪」,便可以直接切换到「文章」视图专注阅读。
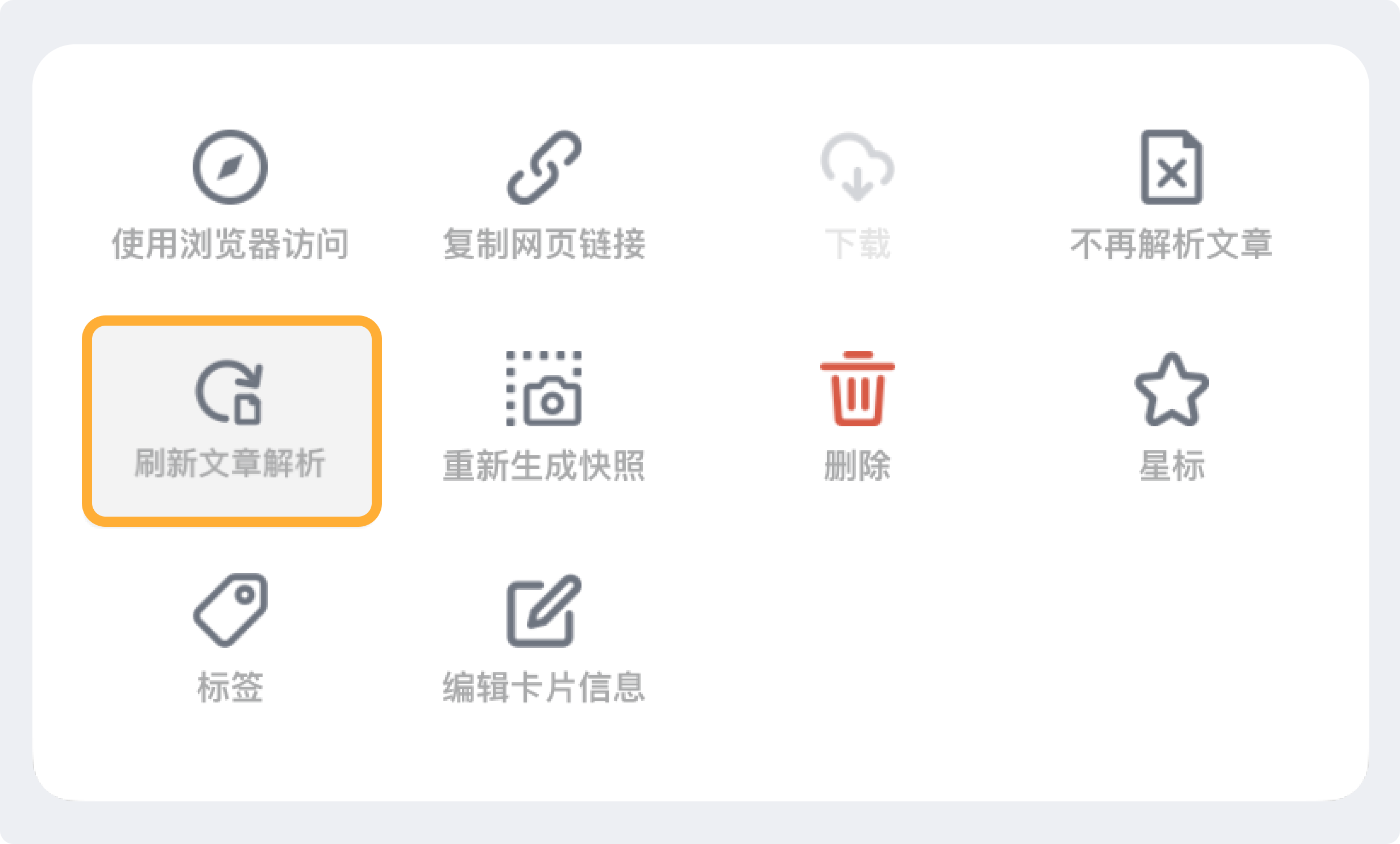
重新解析不满意的文章
如果对文章解析效果不满意(比如之前是直接收藏链接在云端解析的),可以在阅读器中手动「刷新文章解析」,使用本地解析以获得更准确的解析效果。
在云端解析、页面抓取、前端自动解析、手动刷新等多种收藏方式和解析方案的加持下,Cubox 力求无论通过哪种方式汇入的内容,都能获得不错的解析效果,为你的知识管理提供优质素材。
无感、省心的文章解析
- 不同网站千差万别,Cubox 的抓取和解析方案,会在尊重用户隐私和法律法规的前提下进行。
- 我们在乎简单易上手的低门槛,因此很多计算都放在云端处理,这样打开 App 就可以享受到已经就绪的数据,减少等待;
- 我们在乎专业人士的使用体验,因此我们会提供多种措施和手动刷新功能,持续付出努力来一步一步提高哪怕是 10% 的准确率。
